


主要功能点:
先读取每个站点根域下的
robots.txt(例如https://example.com/robots.txt),解析Sitemap:条目(支持多个)。访问每个 sitemap URL;如果是 sitemap index(
<sitemapindex>),会递归解析子 sitemap;如果是普通 urlset(<urlset>),会提取<loc>与<lastmod>(若存在)。对于每个 sitemap URL 条目:若
lastmod存在且在昨天或今天内,则直接把该页面加入候选列表,无需再扫描该站点其它页面。若 robots.txt 没有 sitemap,或 sitemap 解析失败,或 sitemap 中没得到带
lastmod的条目,则退回到之前的“抓取主页并解析页面内链接”方法(原逻辑保持不变)。支持
.xml和.xml.gz(自动解压)。解析使用内建xml.etree.ElementTree。用aiohttp做异步 HTTP 请求(比同步 requests 更适合 async 爬虫)。保持之前所有功能:文章/列表页判定、LLM 日期兜底、AI 相关性判断、双语摘要、中文标题、日期过滤(只保留昨天/今天)、邮件两栏样式与自适应等。
代码如下
#!/usr/bin/env python3
# ai_news_crawler_final.py
# 依赖:
# pip install crawl4ai openai beautifulsoup4 aiohttp python-dateutil premailer
import os
import re
import io
import gzip
import json
import time
import socket
import logging
import asyncio
import smtplib
import aiohttp
import xml.etree.ElementTree as ET
from typing import Optional, List, Dict, Tuple
from datetime import datetime, timedelta, date
from urllib.parse import urlparse, urljoin
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from bs4 import BeautifulSoup
# crawl4ai
from crawl4ai import AsyncWebCrawler
from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfig
# OpenAI-compatible client (use your provided compatible endpoint)
from openai import OpenAI
# optional
try:
from dateutil import parser as date_parser
except Exception:
date_parser = None
try:
from premailer import transform as premailer_transform
except Exception:
premailer_transform = None
# ---------------- Config (env overrideable) ----------------
SITE_ROOTS = ["https://openai.com/zh-Hans-CN/news/"]
CRAWL_DEPTH = int(os.getenv("CRAWL_DEPTH", "2")) # BFS depth to follow links
MAX_LINKS_SCAN = int(os.getenv("MAX_LINKS_SCAN", "200")) # max candidate links to scan
MAX_NEWS = int(os.getenv("MAX_NEWS", "20")) # max articles in email
CONCURRENT_WORKERS = int(os.getenv("CONCURRENT_WORKERS", "10"))
MIN_CONTENT_LENGTH = int(os.getenv("MIN_CONTENT_LENGTH", "80"))
# Keep only articles published on or after YESTERDAY (today - 1 day)
YESTERDAY_DATE = (datetime.now() - timedelta(days=1)).date()
# OpenAI config
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise RuntimeError("Please set OPENAI_API_KEY environment variable.")
openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
LLM_MODEL = os.getenv("LLM_MODEL", "deepseek-v3")
# SMTP config
SMTP_SERVER = "smtp.qiye.aliyun.com"
SMTP_PORT = int(os.getenv("SMTP_PORT", 465))
SMTP_USER = os.getenv("SMTP_USER", "xxxx")
SMTP_PASS = os.getenv("SMTP_PASS", "xxx")
EMAIL_TO = os.getenv("EMAIL_TO", "xxxx")
EMAIL_FROM = os.getenv("EMAIL_FROM", SMTP_USER)
TODAY_DATE = date.today()
# Listing detection & thresholds
USE_LLM_FOR_LISTING = os.getenv("USE_LLM_FOR_LISTING", "false").lower() in ("1", "true", "yes")
LISTING_MIN_CARDS = int(os.getenv("LISTING_MIN_CARDS", "3"))
LISTING_CARD_TEXT_MAX_WORDS = int(os.getenv("LISTING_CARD_TEXT_MAX_WORDS", "200"))
LISTING_LINK_WORD_RATIO = float(os.getenv("LISTING_LINK_WORD_RATIO", "0.05"))
LISTING_MIN_LINKS = int(os.getenv("LISTING_MIN_LINKS", "10"))
ARTICLE_MIN_WORDS = int(os.getenv("ARTICLE_MIN_WORDS", "300"))
ARTICLE_MIN_PARAS = int(os.getenv("ARTICLE_MIN_PARAS", "5"))
# runtime tuning
PAGE_FETCH_ATTEMPTS = 2
PAGE_FETCH_SLEEP = 0.6
LLM_SLEEP = 0.35
EMAIL_MAX_RETRIES = 3
LLM_DATE_ATTEMPTS = 2
logging.basicConfig(level=logging.INFO, format="%(asctime)s [%(levelname)s] %(message)s")
# ---------------- OpenAI async wrapper ----------------
async def openai_chat_async(prompt: str, max_tokens: int = 512, temperature: float = 0.0) -> str:
def _call():
resp = openai_client.chat.completions.create(
model=LLM_MODEL,
messages=[{"role": "user", "content": prompt}],
temperature=float(temperature),
max_tokens=int(max_tokens),
)
try:
return resp.choices[0].message.content.strip()
except Exception:
try:
return resp.choices[0].text.strip()
except Exception:
return str(resp)
return await asyncio.to_thread(_call)
# ---------------- robots.txt & sitemap parsing ----------------
async def fetch_text(session: aiohttp.ClientSession, url: str, timeout: int = 20) -> Optional[bytes]:
try:
async with session.get(url, timeout=timeout, headers={"User-Agent": "ai-news-crawler/1.0"}) as resp:
if resp.status != 200:
logging.debug("fetch_text %s -> status %s", url, resp.status)
return None
return await resp.read()
except Exception as e:
logging.debug("fetch_text fail %s: %s", url, e)
return None
async def parse_robots_for_sitemaps(session: aiohttp.ClientSession, domain_root: str) -> List[str]:
robots_url = urljoin(domain_root.rstrip("/"), "/robots.txt")
b = await fetch_text(session, robots_url)
if not b:
logging.debug("No robots.txt content for %s", robots_url)
return []
try:
text = b.decode("utf-8")
except Exception:
text = b.decode("utf-8", errors="ignore")
sample = "\n".join(text.splitlines()[:8])
logging.debug("robots.txt (%s) sample:\n%s", robots_url, sample)
sitemaps = []
for line in text.splitlines():
if not line:
continue
line_no_comment = line.split("#", 1)[0].strip()
if not line_no_comment:
continue
if re.match(r'(?i)^\s*sitemap\s*:', line_no_comment):
parts = line_no_comment.split(":", 1)
if len(parts) > 1:
v = parts[1].strip()
if v:
abs_url = urljoin(domain_root, v)
sitemaps.append(abs_url)
if not sitemaps:
found = re.findall(r'(?im)^\s*Sitemap:\s*(\S+)', text)
for v in found:
abs_url = urljoin(domain_root, v.strip())
sitemaps.append(abs_url)
seen = set()
out = []
for s in sitemaps:
if s not in seen:
seen.add(s)
out.append(s)
logging.info("parse_robots_for_sitemaps(%s) -> %d sitemaps", domain_root, len(out))
if len(out) == 0:
logging.debug("robots.txt content did not reveal sitemaps for %s", domain_root)
else:
logging.debug("Sitemaps: %s", out)
return out
def _try_parse_xml_bytes(b: bytes) -> Optional[ET.Element]:
try:
return ET.fromstring(b)
except ET.ParseError:
try:
return ET.fromstring(b.decode("utf-8", errors="ignore"))
except Exception:
return None
async def parse_sitemap_xml_bytes(b: bytes, base_url: str = "") -> Tuple[List[str], List[Tuple[str, Optional[str]]]]:
try:
if (len(b) >= 2 and b[:2] == b'\x1f\x8b') or base_url.endswith(".gz"):
try:
with gzip.GzipFile(fileobj=io.BytesIO(b)) as gz:
decompressed = gz.read()
b2 = decompressed
except Exception:
b2 = b
else:
b2 = b
except Exception:
b2 = b
root = _try_parse_xml_bytes(b2)
if root is None:
return [], []
def localname(t):
return t.split("}")[-1].lower() if "}" in t else t.lower()
child_sitemaps = []
url_entries = []
if localname(root.tag) == "sitemapindex":
for s in root.findall(".//"):
if localname(s.tag) == "sitemap":
loc = None
for c in s:
if localname(c.tag) == "loc":
loc = c
break
if loc is not None and loc.text:
child_sitemaps.append(loc.text.strip())
elif localname(root.tag) == "urlset":
for u in root.findall(".//"):
if localname(u.tag) == "url":
loc_el = None
last_el = None
for c in u:
if localname(c.tag) == "loc":
loc_el = c
if localname(c.tag) == "lastmod":
last_el = c
loc = loc_el.text.strip() if (loc_el is not None and loc_el.text) else None
last = last_el.text.strip() if (last_el is not None and last_el.text) else None
if loc:
url_entries.append((loc, last))
else:
for u in root.findall(".//"):
if localname(u.tag) == "url":
loc_el = None
last_el = None
for c in u:
if localname(c.tag) == "loc":
loc_el = c
if localname(c.tag) == "lastmod":
last_el = c
loc = loc_el.text.strip() if (loc_el is not None and loc_el.text) else None
last = last_el.text.strip() if (last_el is not None and last_el.text) else None
if loc:
url_entries.append((loc, last))
for s in root.findall(".//"):
if localname(s.tag) == "sitemap":
loc_el = None
for c in s:
if localname(c.tag) == "loc":
loc_el = c
break
if loc_el is not None and loc_el.text:
child_sitemaps.append(loc_el.text.strip())
return child_sitemaps, url_entries
def parse_lastmod_to_date(lastmod: Optional[str]) -> Optional[date]:
if not lastmod:
return None
s = lastmod.strip()
if date_parser:
try:
dt = date_parser.parse(s, fuzzy=True)
return dt.date()
except Exception:
pass
m = re.search(r"(\d{4})-(\d{1,2})-(\d{1,2})", s)
if m:
try:
return date(int(m.group(1)), int(m.group(2)), int(m.group(3)))
except Exception:
pass
m2 = re.search(r"(20\d{6})", s)
if m2:
try:
return datetime.strptime(m2.group(1), "%Y%m%d").date()
except Exception:
pass
return None
async def collect_urls_from_sitemaps(session: aiohttp.ClientSession, sitemap_url: str, max_depth: int = 3) -> List[Tuple[str, Optional[date]]]:
result = []
seen_sitemaps = set()
to_process = [(sitemap_url, 0)]
while to_process:
url, depth = to_process.pop(0)
if url in seen_sitemaps:
continue
if depth > max_depth:
continue
seen_sitemaps.add(url)
b = await fetch_text(session, url)
if not b:
continue
child_smaps, url_entries = await parse_sitemap_xml_bytes(b, base_url=url)
for loc, last in url_entries:
dt = parse_lastmod_to_date(last)
result.append((loc, dt))
for cs in child_smaps:
cs_full = urljoin(url, cs)
if cs_full not in seen_sitemaps:
to_process.append((cs_full, depth + 1))
return result
# ---------------- page fetch + normalize + extraction ----------------
async def fetch_page_with_retries(crawler, url: str, attempts: int = PAGE_FETCH_ATTEMPTS) -> Optional[str]:
last_exc = None
for i in range(attempts):
try:
res = await crawler.arun(url=url, config=CrawlerRunConfig())
html = None
if hasattr(res, "cleaned_html") and res.cleaned_html:
html = res.cleaned_html
elif hasattr(res, "html") and res.html:
html = res.html
else:
try:
d = res.to_dict()
html = d.get("cleaned_html") or d.get("html") or (d.get("markdown") if isinstance(d.get("markdown"), str) else None)
except Exception:
html = None
if html and isinstance(html, str) and html.strip():
return html
last_exc = RuntimeError("No html from crawler")
except Exception as e:
last_exc = e
await asyncio.sleep(PAGE_FETCH_SLEEP * (i + 1))
logging.warning("Failed to fetch %s: %s", url, last_exc)
return None
def normalize_links_from_html(html: str, base_url: str) -> List[str]:
if not html:
return []
soup = BeautifulSoup(html, "html.parser")
anchors = soup.find_all("a", href=True)
seen = set()
parsed = []
parsed_base = urlparse(base_url)
base_root = f"{parsed_base.scheme}://{parsed_base.netloc}"
for a in anchors:
href = a.get("href").strip()
if href.startswith("#") or href.lower().startswith("mailto:") or href.lower().startswith("javascript:"):
continue
full = urljoin(base_root, href)
try:
if urlparse(full).netloc != parsed_base.netloc:
continue
except Exception:
continue
full = full.split("#")[0]
if full not in seen:
seen.add(full)
parsed.append(full)
if len(parsed) >= MAX_LINKS_SCAN:
break
return parsed
def extract_main_fields(html: str, url: Optional[str] = None) -> Dict[str, str]:
soup = BeautifulSoup(html or "", "html.parser")
title = ""
h1 = soup.find("h1")
if h1 and h1.get_text(strip=True):
title = h1.get_text(strip=True)
else:
og = soup.find("meta", property="og:title")
if og and og.get("content"):
title = og.get("content").strip()
elif soup.title and soup.title.get_text(strip=True):
title = soup.title.get_text(strip=True)
date_str = ""
time_tag = soup.find("time")
if time_tag:
date_str = (time_tag.get("datetime") or time_tag.get_text(strip=True) or "").strip()
if not date_str:
metas = [
{"property": "article:published_time"},
{"name": "date"},
{"name": "pubdate"},
{"name": "publishdate"},
{"name": "datePublished"},
]
for attrs in metas:
tag = soup.find("meta", attrs=attrs)
if tag and tag.get("content"):
date_str = tag.get("content").strip()
break
if not date_str:
candidates = soup.select(".meta, .post-meta, .publish-date, .pubtime, .time, .article-meta, .post-date, .entry-meta, .byline")
for c in candidates[:10]:
txt = c.get_text(" ", strip=True)
if not txt or len(txt) > 160:
continue
if "|" in txt:
parts = [p.strip() for p in txt.split("|") if p.strip()]
for p in reversed(parts):
if re.search(r"\d{4}|[A-Za-z]{3,9}\s+\d{1,2},\s*\d{4}|月", p):
date_str = p
break
if date_str:
break
if re.search(r"\d{4}[/-]\d{1,2}[/-]\d{1,2}|\b[A-Za-z]{3,9}\s+\d{1,2},\s*\d{4}\b|\d{1,2}月", txt):
date_str = txt
break
if not date_str:
top_text = soup.get_text(" ", strip=True)[:1000]
m = re.search(r"\d{4}[/-]\d{1,2}[/-]\d{1,2}", top_text)
if m:
date_str = m.group(0)
content_text = ""
article_tag = soup.find("article")
if article_tag and article_tag.get_text(strip=True):
content_text = article_tag.get_text(" ", strip=True)
else:
selectors = ["div[class*='content']", "div[class*='article']", "div[id*='content']", "div[class*='post']", "div[class*='main']", "div[class*='entry']"]
for sel in selectors:
tag = soup.select_one(sel)
if tag and tag.get_text(strip=True):
content_text = tag.get_text(" ", strip=True)
break
if not content_text:
ps = soup.find_all("p")
if ps:
content_text = " ".join([p.get_text(" ", strip=True) for p in ps if p.get_text(strip=True)])
return {"title": title or "", "date_str": date_str or "", "content": content_text or "", "url": url or ""}
def parse_date_string_to_dt(date_str: str) -> Optional[datetime]:
if not date_str:
return None
s = date_str.strip()
if "|" in s:
parts = [p.strip() for p in s.split("|") if p.strip()]
for p in reversed(parts):
dt = parse_date_string_to_dt(p)
if dt:
return dt
s = parts[-1] if parts else s
s = re.sub(r"^(Posted|Published|Updated|Event|Release|Date)[:\s\-–—]*", "", s, flags=re.I).strip()
s = s.strip(" ,;")
if date_parser:
try:
dt = date_parser.parse(s, fuzzy=True, default=datetime(datetime.now().year,1,1))
if 1900 <= dt.year <= datetime.now().year + 1:
return dt
except Exception:
pass
m = re.search(r"(\d{4})[^\d](\d{1,2})[^\d](\d{1,2})", s)
if m:
try:
y, mo, d = int(m.group(1)), int(m.group(2)), int(m.group(3))
if 1900 <= y <= datetime.now().year + 1:
return datetime(y, mo, d)
except Exception:
pass
m2 = re.search(r"\b([A-Za-z]{3,9})\s+(\d{1,2}),\s*(\d{4})\b", s)
if m2:
try:
month_name, day, year = m2.group(1), int(m2.group(2)), int(m2.group(3))
try:
dt = datetime.strptime(f"{month_name} {day} {year}", "%B %d %Y")
except ValueError:
dt = datetime.strptime(f"{month_name} {day} {year}", "%b %d %Y")
if 1900 <= dt.year <= datetime.now().year + 1:
return dt
except Exception:
pass
m3 = re.search(r"(\d{4})年\s*(\d{1,2})月\s*(\d{1,2})日", s)
if m3:
try:
y, mo, d = int(m3.group(1)), int(m3.group(2)), int(m3.group(3))
if 1900 <= y <= datetime.now().year + 1:
return datetime(y, mo, d)
except Exception:
pass
m4 = re.search(r"(\d{1,2})月\s*(\d{1,2})日", s)
if m4:
try:
mo, d = int(m4.group(1)), int(m4.group(2))
y = datetime.now().year
candidate = datetime(y, mo, d)
if candidate.date() > TODAY_DATE:
candidate = datetime(y - 1, mo, d)
return candidate
except Exception:
pass
m5 = re.search(r"\b([A-Za-z]{3,9})\s+(\d{1,2})\b", s)
if m5:
try:
month_name, day = m5.group(1), int(m5.group(2))
try:
candidate = datetime.strptime(f"{month_name} {day} {datetime.now().year}", "%B %d %Y")
except ValueError:
candidate = datetime.strptime(f"{month_name} {day} {datetime.now().year}", "%b %d %Y")
if candidate.date() > TODAY_DATE:
candidate = candidate.replace(year=candidate.year - 1)
return candidate
except Exception:
pass
return None
def extract_date_from_url(url: str) -> Optional[datetime]:
if not url:
return None
m = re.search(r"/(20\d{2})[/-](\d{1,2})[/-](\d{1,2})/", url)
if m:
try:
return datetime(int(m.group(1)), int(m.group(2)), int(m.group(3)))
except Exception:
pass
m2 = re.search(r"/(20\d{6})/", url)
if m2:
s = m2.group(1)
try:
return datetime.strptime(s, "%Y%m%d")
except Exception:
pass
m3 = re.search(r"/(20\d{2})/(\d{1,2})/(\d{1,2})(?:/|$)", url)
if m3:
try:
return datetime(int(m3.group(1)), int(m3.group(2)), int(m3.group(3)))
except Exception:
pass
return None
# ---------------- LLM helpers ----------------
async def llm_extract_date(title: str, content: str, html_snippet: str = "") -> Optional[datetime]:
if not title and not content and not html_snippet:
return None
prompt = (
"你是一个日期抽取助手。请从下面的新闻信息中判断文章的创建/发布日期(优先使用页面上明确的发布时间)。\n"
"严格只返回 YYYY-MM-DD 或 NONE(若无法确定)。不要输出其它文字。\n\n"
f"标题: {title}\n\n正文或页面片段:\n{content[:1400]}\n\n"
)
if html_snippet:
prompt += f"页面片段:\n{html_snippet[:1200]}\n\n"
prompt += "只返回 YYYY-MM-DD 或 NONE。"
for attempt in range(1, LLM_DATE_ATTEMPTS + 1):
try:
text = await openai_chat_async(prompt, max_tokens=32, temperature=0.0)
text = text.strip()
text = re.sub(r"^```+|```+$", "", text).strip()
m = re.search(r"(\d{4}[/-]\d{1,2}[/-]\d{1,2})", text)
if m:
date_text = m.group(1).replace("/", "-")
try:
dt = datetime.strptime(date_text, "%Y-%m-%d")
if dt.date() > TODAY_DATE:
logging.info("LLM returned future date %s — treating as NONE", dt.date())
return None
if 1900 <= dt.year <= datetime.now().year + 1:
await asyncio.sleep(LLM_SLEEP)
return dt
except Exception:
pass
if re.search(r"\bNONE\b", text, flags=re.I):
return None
except Exception as e:
logging.warning("LLM date attempt failed (%d): %s", attempt, e)
await asyncio.sleep(1.0 * attempt)
return None
async def llm_is_ai_related(title: str, content: str) -> bool:
prompt = (
"你是新闻分类助手。判断下面新闻是否与人工智能(AI)直接相关,"
"包括机器学习、深度学习、生成式AI、大模型、NLP、CV、AI芯片/推理等。仅返回 YES 或 NO。\n\n"
f"标题: {title}\n\n内容片段: {content[:1200]}\n\n"
)
try:
text = await openai_chat_async(prompt, max_tokens=32, temperature=0.0)
text = text.strip().upper()
await asyncio.sleep(LLM_SLEEP)
return "YES" in text
except Exception as e:
logging.warning("LLM classify error: %s", e)
return False
async def llm_bilingual_summary(title: str, content: str) -> Dict[str, str]:
prompt = (
"请为下面的新闻生成简洁的中英文对照摘要(中文不超过100字,英文不超过80词)。"
"请仅以 JSON 格式返回:{\"zh\":\"中文摘要\",\"en\":\"English summary\"},不要其它说明。\n\n"
f"标题: {title}\n\n内容(片段): {content[:1600]}\n\n"
)
try:
out = await openai_chat_async(prompt, max_tokens=400, temperature=0.25)
out = out.strip()
await asyncio.sleep(LLM_SLEEP)
out_clean = re.sub(r"^```(?:json)?\s*|```$", "", out, flags=re.I).strip()
try:
parsed = json.loads(out_clean)
return {"zh": parsed.get("zh", "").strip(), "en": parsed.get("en", "").strip()}
except Exception:
m_zh = re.search(r"中文\s*[::]\s*(.+)", out, flags=re.I | re.S)
m_en = re.search(r"English\s*[::]\s*(.+)", out, flags=re.I | re.S)
zh = m_zh.group(1).strip() if m_zh else ""
en = m_en.group(1).strip() if m_en else ""
if not (zh and en):
lines = [ln.strip() for ln in out.splitlines() if ln.strip()]
if len(lines) >= 2:
zh = zh or lines[0]
en = en or lines[1]
else:
zh = zh or out
en = en or out
return {"zh": zh, "en": en}
except Exception as e:
logging.warning("LLM summary error: %s", e)
return {"zh": "", "en": ""}
async def llm_translate_title_to_chinese(title: str) -> Optional[str]:
if not title:
return None
prompt = (
"请将下面的英文新闻标题翻译成简洁、可读的中文标题。"
"只返回中文标题一句,不要添加其他解释或标点。\n\n"
f"Title: {title}\n\n"
)
try:
out = await openai_chat_async(prompt, max_tokens=64, temperature=0.2)
out = out.strip()
out = re.sub(r"^```+|```+$", "", out).strip()
await asyncio.sleep(LLM_SLEEP)
first_line = out.splitlines()[0].strip() if out else None
return first_line or None
except Exception as e:
logging.warning("LLM translate title failed: %s", e)
return None
def title_is_english_only(title: str) -> bool:
if not title:
return False
if re.search(r"[\u4e00-\u9fff\u3400-\u4dbf\u3000-\u303f]", title):
return False
if re.search(r"[A-Za-z]", title):
return True
return False
# ---------------- Listing detection (conservative) ----------------
def _is_nav_or_footer_tag(tag):
for p in tag.parents:
name = (p.name or "").lower()
cls = " ".join(p.get("class") or []).lower()
if name in ("nav", "footer", "header") or "nav" in cls or "footer" in cls:
return True
return False
def _jsonld_contains_article(soup: BeautifulSoup) -> bool:
try:
for s in soup.find_all("script", type="application/ld+json"):
try:
payload = json.loads(s.string or "{}")
except Exception:
continue
arr = payload if isinstance(payload, list) else [payload]
for obj in arr:
if not isinstance(obj, dict):
continue
t = obj.get("@type") or obj.get("type") or ""
if isinstance(t, list):
types = [x.lower() for x in t if isinstance(x, str)]
else:
types = [t.lower()] if isinstance(t, str) else []
for ty in types:
if "article" in ty or "newsarticle" in ty:
return True
except Exception:
pass
return False
async def is_listing_page_async(html: str, url: str, use_llm: bool = USE_LLM_FOR_LISTING) -> bool:
if not html:
return False
soup = BeautifulSoup(html, "html.parser")
og_tag = soup.find("meta", property="og:type")
if og_tag and og_tag.get("content") and og_tag.get("content").strip().lower() == "article":
return False
try:
if _jsonld_contains_article(soup):
return False
except Exception:
pass
article_tag = soup.find("article")
if article_tag:
article_text = article_tag.get_text(" ", strip=True)
words = len(article_text.split())
paras = len(article_tag.find_all("p"))
if words >= ARTICLE_MIN_WORDS or paras >= ARTICLE_MIN_PARAS:
return False
possible_body_selectors = ["div[class*='article__body']", "div[class*='article-body']", "div[class*='post-body']", "div[class*='entry-content']", "div[class*='content-body']"]
for sel in possible_body_selectors:
el = soup.select_one(sel)
if el:
txt = el.get_text(" ", strip=True)
if len(txt.split()) >= ARTICLE_MIN_WORDS:
return False
card_selectors = [
"article",
"div[class*='card']",
"div[class*='teaser']",
"div[class*='post']",
"div[class*='item']",
"li[class*='item']",
"div[class*='entry']",
"section[class*='list']",
"ul[class*='list'] li",
]
card_count = 0
for sel in card_selectors:
for el in soup.select(sel):
if _is_nav_or_footer_tag(el):
continue
anchors = el.find_all("a", href=True)
imgs = el.find_all("img")
txt = el.get_text(" ", strip=True)
words = len(txt.split())
if len(anchors) >= 1 and (len(imgs) >= 1 or words <= LISTING_CARD_TEXT_MAX_WORDS):
card_count += 1
main = soup.find("main") or soup.find("body")
main_text = (main.get_text(" ", strip=True) if main else "")
if card_count >= LISTING_MIN_CARDS and len(main_text.split()) < ARTICLE_MIN_WORDS:
return True
words = len(main_text.split())
links = len(main.find_all("a", href=True)) if main else 0
if words > 0 and links > 0:
ratio = links / max(words, 1)
if ratio >= LISTING_LINK_WORD_RATIO and links >= LISTING_MIN_LINKS and words < ARTICLE_MIN_WORDS:
return True
heading_links = 0
heading_total = 0
for h in soup.find_all(["h2", "h3"]):
heading_total += 1
if h.find("a", href=True):
heading_links += 1
if heading_total >= 3 and heading_links / heading_total >= 0.6 and len(main_text.split()) < ARTICLE_MIN_WORDS:
return True
if re.search(r"pagination|page-nav|next|prev|older|newer|page \d+|加载更多|更多", html, re.I) and len(main_text.split()) < ARTICLE_MIN_WORDS:
return True
if re.search(r"/(category|tag|topics?|topic|section|archives|archive|category-)", url, re.I) and len(main_text.split()) < ARTICLE_MIN_WORDS:
return True
if use_llm:
try:
snippet = (main_text[:1800] or soup.get_text(" ", strip=True)[:1800])
prompt = (
"请判断下面的网页片段是“文章列表/索引页面”(LIST)还是“单篇文章”(ARTICLE)。\n"
"只返回 LIST 或 ARTICLE,不要其它文字。\n\n"
f"URL: {url}\n\n片段:\n{snippet}\n"
)
res = await openai_chat_async(prompt, max_tokens=32, temperature=0.0)
if res:
if re.search(r"\bLIST\b", res, re.I) and not re.search(r"\bARTICLE\b", res, re.I):
return True
if re.search(r"\bARTICLE\b", res, re.I) and not re.search(r"\bLIST\b", res, re.I):
return False
except Exception as e:
logging.debug("LLM list detection failed: %s", e)
return False
# ---------------- Email HTML ----------------
def build_email_html(items: List[Dict]) -> str:
updated = datetime.now().strftime("%Y-%m-%d %H:%M")
total = len(items)
html_parts = []
html_parts.append(f"""<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>AI 新闻精选</title>
<style>
@media only screen and (max-width:600px), only screen and (max-device-width:600px) {{
.two-col {{ display:block !important; width:100% !important; }}
.col {{ display:block !important; width:100% !important; }}
}}
.button {{ display:inline-block; text-decoration:none; border-radius:6px; padding:8px 12px; }}
</style>
</head>
<body style="margin:0;padding:0;background:#f4f6f8;font-family:Arial,Helvetica,sans-serif;">
<table width="100%" cellpadding="0" cellspacing="0" role="presentation">
<tr><td align="center" style="padding:18px 12px;">
<table width="720" cellpadding="0" cellspacing="0" role="presentation" style="max-width:720px;width:100%;background:#ffffff;border-radius:6px;overflow:hidden;">
<tr><td style="padding:18px 20px 10px 20px;">
<h1 style="margin:0;font-size:20px;color:#0b5bbb;">🤖 AI 新闻精选</h1>
<p style="margin:6px 0 0 0;color:#666;font-size:13px;">更新:{updated} · 共 {total} 条</p>
</td></tr>
<tr><td style="padding:8px 14px 18px 14px;">
<table width="100%" cellpadding="0" cellspacing="0" role="presentation">
""")
for i in range(0, len(items), 2):
left = items[i]
right = items[i+1] if i+1 < len(items) else None
html_parts.append("<tr class='two-col'>")
for col_item in (left, right):
if not col_item:
html_parts.append("<td class='col' width='50%' style='width:50%;display:inline-block;vertical-align:top;padding:8px;box-sizing:border-box;'></td>")
continue
title = (col_item.get("title") or "").replace('"', '"')
title_cn = col_item.get("title_cn") or ""
date_str = col_item.get("date_display") or "日期未知"
zh = (col_item.get("summary", {}).get("zh") or "").replace('\n', '<br/>')
en = (col_item.get("summary", {}).get("en") or "").replace('\n', '<br/>')
url = col_item.get("url") or "#"
cell = f"""
<td class='col' width='50%' valign='top' style='width:50%;display:inline-block;vertical-align:top;padding:8px;box-sizing:border-box;'>
<table width='100%' cellpadding='0' cellspacing='0' role='presentation' style='background:#fbfbfc;border:1px solid #eef0f3;border-radius:6px;'>
<tr><td style='padding:12px;'>
<div style='font-size:15px;font-weight:700;color:#0b5bbb;margin-bottom:6px;'><a href="{url}" style="color:#0b5bbb;text-decoration:none;">{title}</a></div>
{f'<div style="font-size:13px;color:#333;margin-bottom:8px;">{title_cn}</div>' if title_cn else ''}
<div style='font-size:13px;color:#111;line-height:1.5;'><strong>中文摘要:</strong><div style='margin-top:6px;color:#222'>{zh}</div></div>
<div style='font-size:12px;color:#444;margin-top:8px;'><strong>English:</strong><div style='margin-top:6px;color:#555'>{en}</div></div>
<div style='font-size:12px;color:#888;margin-top:10px;'>发布时间:{date_str}</div>
<div style='margin-top:10px;'><a href="{url}" class="button" style="background:#0b5bbb;color:#fff;font-size:13px;">阅读全文</a></div>
</td></tr>
</table>
</td>
"""
html_parts.append(cell)
html_parts.append("</tr>")
html_parts.append("""
</table>
</td></tr>
<tr><td style="padding:12px 18px 18px 18px;">
<div style="font-size:12px;color:#8892a0;">此邮件由自动化爬虫生成。如需调整接收频率或内容,请联系管理员。</div>
</td></tr>
</table>
</td></tr>
</table>
</body>
</html>
""")
html = "".join(html_parts)
if premailer_transform:
try:
return premailer_transform(html)
except Exception:
return html
return html
# ---------------- sitemap-based candidate collection ----------------
async def collect_candidates_via_sitemaps(session: aiohttp.ClientSession, site_root: str) -> List[str]:
domain_parsed = urlparse(site_root)
domain_root = f"{domain_parsed.scheme}://{domain_parsed.netloc}"
sitemaps = await parse_robots_for_sitemaps(session, domain_root)
if not sitemaps:
logging.info("No sitemaps found in robots for %s", domain_root)
return []
recent_urls = []
for sm in sitemaps:
try:
entries = await collect_urls_from_sitemaps(session, sm)
for loc, lastdt in entries:
if lastdt:
if YESTERDAY_DATE <= lastdt <= TODAY_DATE:
recent_urls.append(loc)
else:
continue
except Exception as e:
logging.warning("Failed parse sitemap %s: %s", sm, e)
# dedupe preserve order
seen = set()
out = []
for u in recent_urls:
if u not in seen:
seen.add(u)
out.append(u)
return out
async def collect_candidate_links(crawler: AsyncWebCrawler, root_url: str, max_depth: int) -> List[str]:
async with aiohttp.ClientSession() as session:
try:
urls_from_sitemap = await collect_candidates_via_sitemaps(session, root_url)
if urls_from_sitemap:
logging.info("Sitemap fast-path found %d recent URLs for %s", len(urls_from_sitemap), root_url)
return urls_from_sitemap
except Exception as e:
logging.debug("Sitemap path failed for %s: %s", root_url, e)
logging.info("Falling back to link scanning for %s", root_url)
root_parsed = urlparse(root_url)
seen = []
queue = [(root_url, 0)]
visited = set([root_url])
while queue and len(seen) < MAX_LINKS_SCAN:
url, depth = queue.pop(0)
if depth > max_depth:
continue
html = await fetch_page_with_retries(crawler, url)
if not html:
continue
links = normalize_links_from_html(html, root_url)
for l in links:
if l not in visited:
visited.add(l)
queue.append((l, depth + 1))
seen.append(l)
if len(seen) >= MAX_LINKS_SCAN:
break
return seen
# ---------------- main per-link processing ----------------
async def process_link(crawler: AsyncWebCrawler, link: str) -> Optional[Dict]:
html = await fetch_page_with_retries(crawler, link)
if not html:
return None
try:
if await is_listing_page_async(html, link):
logging.info("Skipped list/index page: %s", link)
return None
except Exception as e:
logging.debug("Listing detection error for %s: %s", link, e)
fields = extract_main_fields(html, url=link)
title = fields.get("title", "").strip()
content = fields.get("content", "").strip()
date_raw = fields.get("date_str", "").strip()
if not title and not content:
return None
if len(content) < MIN_CONTENT_LENGTH:
return None
parsed_dt = parse_date_string_to_dt(date_raw) if date_raw else None
if not parsed_dt:
m = re.search(r"\d{4}[/-]\d{1,2}[/-]\d{1,2}", html)
if m:
parsed_dt = parse_date_string_to_dt(m.group(0))
if not parsed_dt:
parsed_dt = extract_date_from_url(link)
if not parsed_dt:
try:
snippet = BeautifulSoup(html, "html.parser").get_text(" ", strip=True)[:1200]
parsed_dt = await llm_extract_date(title, content, snippet)
logging.info("LLM date extraction for %s -> %s", link, parsed_dt)
except Exception as e:
logging.warning("LLM date extraction failed for %s: %s", link, e)
parsed_dt = None
if not parsed_dt:
return None
if parsed_dt.date() < YESTERDAY_DATE:
logging.info("Dropping %s: date %s older than cutoff %s", link, parsed_dt.date(), YESTERDAY_DATE)
return None
if parsed_dt.date() > TODAY_DATE:
logging.info("Dropping %s: date %s is in the future (> %s)", link, parsed_dt.date(), TODAY_DATE)
return None
date_display = parsed_dt.strftime("%Y-%m-%d")
try:
is_ai = await llm_is_ai_related(title, content)
except Exception:
is_ai = False
if not is_ai:
return None
try:
summary = await llm_bilingual_summary(title, content)
except Exception:
summary = {"zh": "", "en": ""}
title_cn = None
try:
if title_is_english_only(title):
title_cn = await llm_translate_title_to_chinese(title)
except Exception:
title_cn = None
return {"url": link, "title": title, "title_cn": title_cn, "date_display": date_display, "summary": summary}
# ---------------- orchestration ----------------
def send_email_html_robust(subject: str, html_content: str) -> bool:
msg = MIMEMultipart("alternative")
msg["Subject"] = subject
msg["From"] = SMTP_USER
msg["To"] = EMAIL_TO
msg.attach(MIMEText(html_content, "html", "utf-8"))
try:
socket.getaddrinfo(SMTP_SERVER, SMTP_PORT)
except Exception as e:
logging.exception("SMTP resolve failed: %s", e)
fallback = f"failed_email_{int(time.time())}.html"
with open(fallback, "w", encoding="utf-8") as f:
f.write(html_content)
logging.error("Saved fallback email to %s", fallback)
return False
for attempt in range(1, EMAIL_MAX_RETRIES + 1):
try:
if SMTP_PORT == 465:
with smtplib.SMTP_SSL(SMTP_SERVER, SMTP_PORT, timeout=30) as server:
server.login(SMTP_USER, SMTP_PASS)
server.sendmail(SMTP_USER, [EMAIL_TO], msg.as_string())
else:
with smtplib.SMTP(SMTP_SERVER, SMTP_PORT, timeout=30) as server:
server.ehlo()
try:
server.starttls()
server.ehlo()
except Exception:
pass
server.login(SMTP_USER, SMTP_PASS)
server.sendmail(SMTP_USER, [EMAIL_TO], msg.as_string())
return True
except Exception as e:
logging.exception("Email send attempt %d failed: %s", attempt, e)
time.sleep(2 ** attempt)
fallback = f"failed_email_{int(time.time())}.html"
with open(fallback, "w", encoding="utf-8") as f:
f.write(html_content)
logging.error("All email attempts failed; saved to %s", fallback)
return False
async def main():
browser_cfg = BrowserConfig(browser_type="chromium", headless=True)
collected = []
async with AsyncWebCrawler(config=browser_cfg) as crawler:
logging.info("Collecting candidates from %d roots (depth=%d)...", len(SITE_ROOTS), CRAWL_DEPTH)
all_candidates = []
for root in SITE_ROOTS:
try:
cands = await collect_candidate_links(crawler, root, CRAWL_DEPTH)
logging.info("Found %d candidates from %s", len(cands), root)
all_candidates.extend(cands)
except Exception as e:
logging.warning("Failed to collect from %s: %s", root, e)
# dedupe preserve order
seen = set()
unique_candidates = []
for u in all_candidates:
if u not in seen:
seen.add(u)
unique_candidates.append(u)
logging.info("Total unique candidates: %d", len(unique_candidates))
sem = asyncio.Semaphore(CONCURRENT_WORKERS)
async def sem_task(link):
async with sem:
return await process_link(crawler, link)
for link in unique_candidates:
if len(collected) >= MAX_NEWS:
break
try:
result = await sem_task(link)
except Exception as e:
logging.warning("Error processing %s: %s", link, e)
continue
if result:
if any(r["url"] == result["url"] or r["title"] == result["title"] for r in collected):
logging.info("Duplicate skipped: %s", result.get("title"))
continue
collected.append(result)
logging.info("Collected %d/%d: %s", len(collected), MAX_NEWS, result.get("title"))
await asyncio.sleep(0.12)
if not collected:
logging.info("No articles collected.")
return
html = build_email_html(collected)
subject = f"AI 新闻精选 — {datetime.now().strftime('%Y-%m-%d')}"
ok = send_email_html_robust(subject, html)
if ok:
logging.info("Email sent with %d articles", len(collected))
else:
logging.error("Email not sent; fallback saved.")
if __name__ == "__main__":
try:
asyncio.run(main())
except KeyboardInterrupt:
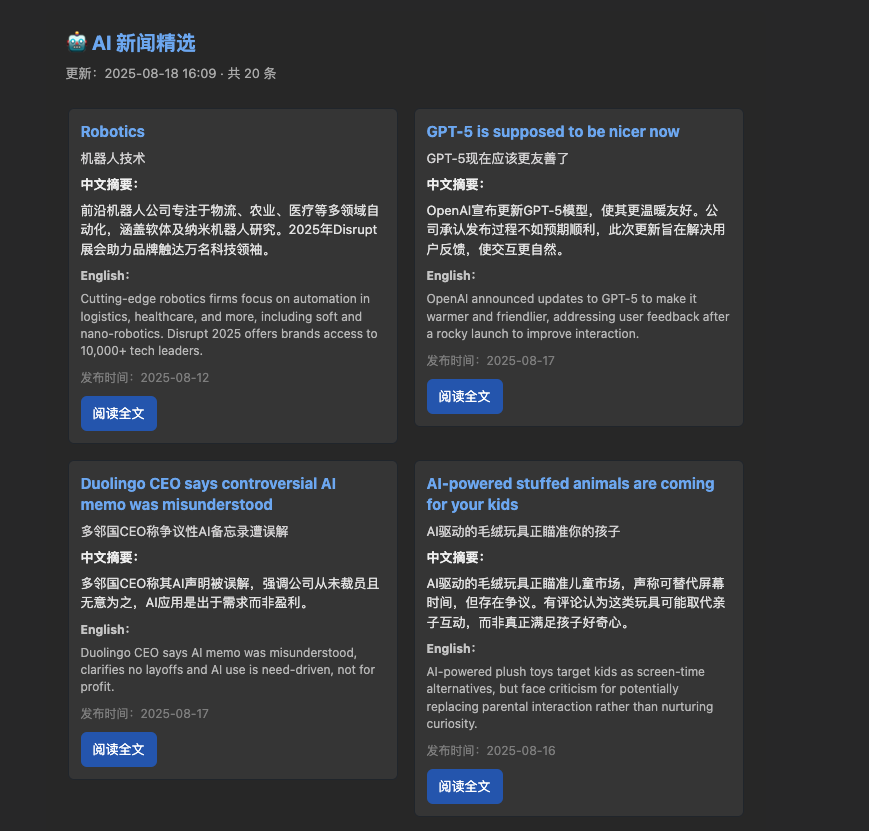
logging.info("Interrupted by user.")最终发送邮件效果图
评论区